
|
|
|---|---|
|
La metodología observacional en el deporte: conceptos básicos
|
|
|
http://www.efdeportes.com/ Revista Digital - Buenos Aires - Año 5 - N° 24 - Agosto de 2000 |
|
6 / 7
9. Tipos de datos
A partir de un tema ya abordado como es el relativo a la toma de decisiones en cuanto a las unidades de observación se refiere, podemos tratar la clasificación de los tipos de datos. Esta clasificación obedece a un doble criterio: ocurrencia y base (Bakeman y Dabbs, 1976; Bakeman, 1978; Anguera, 1988; Anguera et al., 1993). De acuerdo con la ocurrencia los datos pueden ser secuenciales y concurrentes; atendiendo al criterio base se originan el evento y el tiempo. De la combinación de todos resultan cuatro tipo de datos:
OCURRENCIA
Secuencial
Concurrente
BASE
Evento
Tiempo
I
III
II
V
De acuerdo con Anguera (1988), en los Datos tipo I (secuenciales y evento-base) el observador recoge el orden de los eventos, no su duración. El sistema de categorías es mutuamente excluyente y por tanto sólo puede tener lugar una conducta cada vez.
En los Datos tipo II (concurrentes y evento-base), al igual que en los anteriores, se recoge el orden de los eventos sin tener presente su duración, pero con la diferencia de que las categorías son mutuamente excluyentes intranivel y concurrentes internivel5 ; por tanto pueden ocurrir varios eventos al mismo tiempo. Son los datos que ofrecen una mayor dificultad para su análisis.
Por el contrario, en los Datos tipo III (secuenciales y tiempo-base) se anota el orden de ocurrencia de los eventos y su duración. En este tipo de datos las categorías son mutuamente excluyentes. Por lo que respecta al tiempo, se puede conceptualizar como una secuencia de intervalos en los que la unidad de tiempo es menor o igual a la más corta de las conductas.
En cuanto a los Datos tipo IV (concurrentes y tiempo-base) se recoge la duración de los eventos, pudiendo ocurrir éstos simultáneamente. Consecuentemente el sistema de categorías no es mutuamente excluyente.
De acuerdo con lo anterior hay que señalar que el estudio de patrones concurrentes (conductas que co-ocurren y forman un patrón estable) se realiza a partir de los datos tipo IV (Bakeman y Dabbs, 1976; Bakeman, 1978; Anguera, 1988); sin embargo el estudio de patrones secuenciales (estudio de las conductas que preceden o siguen una respecto a otra, mantenimiento de un orden, ciclos repetitivos de una conducta criterio respecto a sí misma) se realiza con datos tipo I y III.
Con el fin de transformar datos para realizar un análisis secuencial, es posible transformar datos con mayor información en otros datos que contienen menos. Así sabemos que, los datos tipo IV, son los que contienen mayor tipo de información, sobre secuencia, co-ocurrencia y tiempo físico. Los datos tipo III contienen información sobre secuencia y tiempo físico pero no sobre co-ocurrencia. Los datos tipo II ofrecen información sobre secuencia y co-ocurrencia, pero no sobre tiempo físico. Los datos tipo I contienen, únicamente, información sobre secuencia. Teniendo en cuenta estos datos podemos transformar, p.e., datos tipo II a tipo I, datos tipo III en datos tipo I, si prescindimos del tiempo físico. También es posible transformar datos tipo IV en datos tipo III.
La finalidad de este tipo de datos fue proporcionar un estándar útil para el intercambio entre investigadores y para la elaboración de programas informáticos que analizasen dichos datos. La desventaja más patente es que obliga al investigador a ceñirse a una representación de datos que pueden no coincidir con los utilizados al recogerlos (Quera, 1993).
Con el fin de solventar la desventaja descrita anteriormente Bakeman y Quera (1995) crearon el Sequential Data Interchange Standard, que potencia el intercambio entre investigadores y el desarrollo de software destinado al análisis secuencial con mayor énfasis que la tipología original de Bakeman (1978). Además, supone una reconceptualización de los datos basada, no tanto en la estructura conceptual de las unidades de conducta (existencia o no de mutua exclusividad y exhaustividad), sino en las técnicas de registro que se emplean habitualmente para recoger datos observacionales.
La tipología de Bakeman y Quera (1995), da lugar a los siguientes tipos de datos: Event Sequential Data (ESD) o Eventos (Secuencias de Eventos), State Sequential Data (SSD) o Estados (Secuencias de Estados), Time Event Sequential Data o Secuencias de Eventos con duración e Interval Sequential Data o Secuencias de Intervalo.
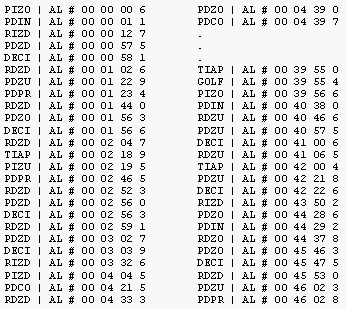
1. Secuencia de Eventos. Las secuencias de eventos o Event Sequential Data (ESD) son series de códigos que representan las ocurrencias de unidades de conducta mutuamente excluyentes que son eventos o bien estados sin registro de duración. Existen dos clases de datos ESD, aquellos en los que ningún código puede repetirse inmediatamente después de sí mismo (ESD no repetibles) y aquellos en los que puede repetirse libremente (ESD repetibles). Estos datos se obtienen a través de un registro activado por transiciones (Quera,1991) y constituye el formato más simple, equivalente a los datos tipo I de Bakeman (1978).
Un ejemplo de este tipo de datos puede ser el recogido en el siguiente fichero del programa CODEX (Hernández Mendo, 19966 ):
Consideremos un sistema de categorías para el estudio de la acción motriz en el fútbol (Hernández Mendo, 1996).
PDPR: Posicionamiento Defensivo organizado de Presión
PDIN: Psicionamiento Defensiva organizada Intermedio
PDCO: Posicionamiento Defensivo organizado de Contención
DECI: Defensa Circunstancial
RDZU: Recuperación directa en área ultraofensiva.
RDZO: Recuperación directa en área ofensiva.
RDZD: Recuperación directa en área defensiva.
RIZU: Recuperación indirecta en área del ultraofensiva.
RIZO: Recuperación indirecta en área ofensiva.
RIZD: Recuperación indirecta en área defensiva.
PDZU: Pérdida directa en área ultraofensiva.
PDZO: Pérdida directa en área ofensiva.
PDZD: Pérdida directa en área defensiva.
PIZU: Pérdida indirecta en área ultraofensiva.
PIZO: Pérdida indirecta en área ofensiva.
PIZD: Pérdida indirecta en área defensiva.
GOLF: Goles a Favor.
GOLE: Goles Encajados.
TIAP: Tiro a Puerta.
RECH: Rechace en Área Contraria.
SEAF: Saques de Esquina a Favor.
SBCC: Saques de Banda en Campo Contrario.
FRCC: Falta Recibida en Campo Contrario.
Esta transcripción contiene 188 registros, aquí nosotros hemos incluido sólo el principio y el final. El partido observado pertenece al fútbol la liga española de primera división de la temporada 1995-1996 entre el Real Madrid y Barcelona. AL es la unidad observada.
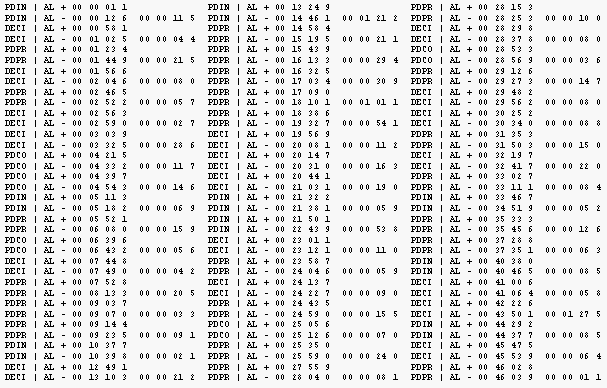
2. Secuencias de Estados. Siguiendo el trabajo de Quera (1993) y Bakeman y Quera (1995, 1996), las secuencias de estados (State Sequential Data, SSD) son series de códigos que representan las ocurrencias de unidades de conducta consideradas como estados. En la serie, cada código va seguido por la duración de la ocurrencia o bien por su tiempo de inicio, expresado en unidades de tiempo físico. Las unidades pueden formar uno o varios conjuntos de unidades EME. En el primer caso, cada sesión de observación se representa mediante una única serie de datos; en el segundo, por tantas series paralelas o simultáneas de datos como conjuntos EME. Los datos tipo III y los IV con unidades temporalmente exhaustivas son casos particulares del tipo SSD. Estos datos se obtienen mediante un registro activado por transiciones en el que se anota, o bien la duración de cada estado, o bien, más comúnmente, el momento de inicio del mismo.
Ejemplo: Si consideramos un sistema de categorías que permiten estudiar los posicionamientos defensivos de los equipos
PDPR: Posicionamiento Defensivo organizado de Presión
PDIN: Posicionamiento Defensiva organizada Intermedio
PDCO: Posicionamiento Defensivo organizado de Contención
DECI: Defensa CircunstancialEsta transcripción contiene 54 registros (108 si nosotros consideramos los principios "+" y los extremos" -"). El partido observado pertenece al fútbol la liga española de primera división de la temporada 1995-1996 entre el Real Madrid y Barcelona. AL es la unidad observada.
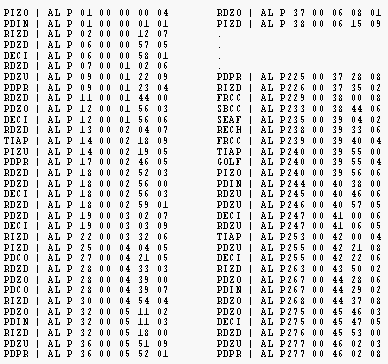
3. Secuencias de Eventos con duración. Según Quera (1993), Bakeman y Quera (1995, 1996) podemos considerar a este tipo de secuencias (Timed Event Sequential Data, TSD) como el tipo de datos más complejos y al contrario que los anteriores, carece de referente en la clasificación ofrecida por Bakeman (1978). En estas series de códigos se representan las ocurrencias de eventos o de estados, no necesariamente exhaustivos ni mutuamente excluyentes. Para construir la secuencia correspondiente, si se trata de un evento, irá seguido por su tiempo de ocurrencia (de forma puntual), por el contrario, si se trata de un estado, va seguido de su tiempo de inicio, o por su tiempo de finalización o por ambos, expresados siempre en unidades de tiempo físico. Estas secuencias pueden estar formadas por eventos, por estados o por una mezcla de ambos. La ordenación de los códigos se realiza atendiendo al tiempo de ocurrencia o de inicio, o bien al de finalización si el código sólo va acompañado por éste.
En este ejemplo utilizaremos el mismo sistema de categorías que el utilizado para los eventos. Esta transcripción contiene 486 registros (incluido los principios "+" y los finales" -" de los estados), aquí nosotros hemos incluido sólo el principio y el final. El partido observado pertenece al fútbol la liga española de primera división de la temporada 1995-1996 entre el Real Madrid y Barcelona. AL es la unidad observada.

4. Secuencias de Intervalos.Al respecto de estos datos Quera (1993) señala que "a diferencia de los tipos anteriores, una secuencia de intervalos (Interval Sequential Data, ISD) se compone de bloques que representan intervalos de tiempo constante, los cuales pueden contener códigos que representan unidades de conducta que han sido registradas en los mismos de acuerdo con una de las tres técnicas más comunes de muestreo de tiempo (o registro activado por unidades de tiempo; Quera, 1991): muestreo instantáneo, de intervalo parcial y de intervalo total. Las unidades de conducta no han de ser necesariamente EME, y pueden o no estar organizadas en varias conjuntos EME. Cada intervalo puede contener desde ninguno a todos los códigos posibles, según la técnica de muestreo empleada y la estructura de las unidades de conducta. Este tipo de datos no tiene equivalente exacto en la tipología de Bakeman (1978), aunque podría asimilarse a unos datos tipo IV en los que cada combinación de unidades de conducta dura exactamente el mismo tiempo, igual a la longitud de intervalo empleada. Sin embargo, mientras que en los datos tipo IV las duraciones son verdaderas, en los TSD de la presencia de un código no puede deducirse su duración, debido a las características de muestreo de tiempo" (p.368).
En este ejemplo utilizaremos el mismo sistema de categorías que el utilizado para los eventos y para los estados. Esta transcripción contiene 189 registros, aquí nosotros hemos incluido sólo el principio y el final. El partido observado pertenece al fútbol la liga española de primera división de la temporada 1995-1996 entre el Real Madrid y Barcelona. La "P" seguida de un número indica el intervalo en el que se encuentra la observación. ANAL es la unidad observada.
10. Diseños observacionales
La metodología observacional adoleció tradicionalmente de líneas de investigación en las cuales se pusieran a prueba las múltiples posibilidades de análisis de sus datos. Probablemente, el principal motivo se halla en la superficialidad con que se obtenían tales datos, y, por consiguiente, en su carácter inconsistente.
En la actualidad, sin embargo, casi al final de la década de los noventa, se ha avanzado en la configuración de los principales diseños observacionales, los cuales son de disposición no estándar en coherencia con el carácter sumamente flexible de la metodología observacional, y si además tenemos en cuenta una sustancial mejora que en la mayoría de los casos se pone en práctica en el proceso de sistematización y optimización de los datos, es lógico que hayan surgido nuevas propuestas en lo que se refiere al análisis de datos.
Por supuesto, se pueden establecer criterios muy diversos en este punto de encrucijada. Desde hace más de una década estamos trabajando con un planteamiento en que se cruzan la dicotomía idiográfico(unidad)/nomotético(pluralidad) y la relativa a un registro puntual/seguimiento, lo cual facilita el deslinde de las direcciones básicas de análisis de datos observacionales.
Con esta propuesta se dispone de cuatro cuadrantes, que corresponderían, salvo en un caso, a los diseños diacrónicos, sincrónicos y mixtos o lag-log, que absorben la totalidad de las contingencias que puedan presentarse (Anguera, 1994; Anguera, Blanco y Losada, 1995):
Cuadrante idiográfico/seguimiento (Diseños diacrónicos). El seguimiento en un estudio idiográfico constituye, por esencia, la situación óptima propia de la metodología observacional, ya que se consigue focalizar toda la atención en una unidad mínima (sea un sujeto, o un pequeño grupo que funcione como unidad, o sea un nivel de respuesta). Por su parte, el seguimiento puede ser de carácter extensivo o intensivo, según, respectivamente, que el parámetro básico utilizado en el registro sea frecuencia, por una parte, o bien orden o duración, por otra. Ello conlleva que puedan diferenciarse diseños diacrónicos extensivos y diseños diacrónicos intensivos: Los primeros, a su vez, y en función del número de puntos de tiempo en que se efectúe el seguimiento, pueden ser de panel, tendenciales, y de series de tiempo; y los segundos, a su vez, permiten el desarrollo de diseños secuenciales.
Cuadrante idiográfico/puntual. Una recogida de datos puntual y a partir de un solo sujeto no es capaz de proporcionar información mínimamente consistente que garantiza la cientificidad del estudio. En consecuencia, se trata del único cuadrante que no ofrece datos válidos para un posterior análisis.
Cuadrante nomotético/puntual (diseños sincrónicos). Cada vez son más frecuentes las situaciones en las que es necesario conocer la distribución de un grupo de sujetos o de varios niveles de respuesta considerados conjuntamente en un momento dado. A su vez, los diseños sincrónicos pueden ser simétricos o asimétricos: Los primeros únicamente se centran en el estudio de la intensidad de conexión entre las diversas unidades, mientras que los segundos incorporan relaciones de causalidad entre ellas.
Cuadrante nomotético/seguimiento (diseños mixtos). El seguimiento de un grupo de sujetos o un conjunto de varios niveles de respuesta es un problema complejo a desglosar. Habrá que tener en cuenta cómo cada uno de los ejes da lugar a diversas posibilidades, que después deberán integrarse. Por una parte, el eje del seguimiento, dará lugar a la dicotomía extensivo/intensivo. El eje de la pluralidad, se puede descomponer, a su vez, y por una parte, en la combinación formada por un individuo y varios niveles de respuesta, un nivel de respuesta y varios individuos, y varios individuos con varios niveles de respuesta; y por otra en la modalidad de interrelación entre las distintas unidades. La integración final de todas las posibilidades da lugar a veinticuatro diseños en que se descompone este cuarto cuadrante.
| Lecturas: Educación Física y Deportes · http://www.efdeportes.com · Año 5 · Nº 24 | sigue Ü |