|
CODEX1: un programa informático para codificación de registros observacionales Antonio Hernández Mendo*, Miguel Angel Bermúdez Rivera** María Teresa Anguera Argilaga*** y José Luis Losada*** (España) * Depto. Psicología Social y de la Personalidad. Facultad de Psicología. Universidad de Málaga ** Universidad de A Coruña *** Universidad de Barcelona mendo@uma.es
Resumen
Abstract |
Lecturas: Educación Física y Deportes | http://www.efdeportes.com/ revista digital | Buenos Aires | Año 5 - Nº 18 - Febrero 2000 |
1 / 2
1. Introducción
Esta implementación informática arranca, en su concepción, del programa TRANSCRIPTOR (Peralbo, Risso, Ramos y Hernández Mendo, 1992; Hernández Mendo, Ramos, Peralbo y Risso, 1993; Hernández Mendo, 1994; Ramos, Hernández Mendo, Peralbo y Risso, 1994; Hernández Mendo, 1996a; Hernández Mendo y Ramos, 1996; Hernández Mendo y Ramos, en prensa a). Con esta nueva herramienta informática pretendemos mejorar las prestaciones de aquel, ofreciendo un programa de codificación que permita registrar el flujo conductual en cualquier situación (ya sea en observaciones in situ o grabadas previamente en soporte magnético -video o audio- de conductas -motoras o verbales-) utilizando la sintaxis propuesta por Bakeman y Quera (1995, 1996) y que permita exportar los datos a los programas SEQUENTIAL DATA INTERCHANGE STANDARD (Bakeman y Quera, 1995), OBSERVER 3.0 (Noldus, 1991), THEME (Magnusson, 1988) y a otros programas de carácter general como paquetes estadísticos (SPSS, BMDP, SYSTAT, etc.), procesadores de texto (Word Perfect, Word, etc.), hojas de cálculo (EXCEL, LOTUS, etc.) y tarjetas de sonido (SOUND BLASTER, etc.). Además de esta función importa los datos procedentes de ficheros creados con el programa TRANSCRIPTOR permitiendo, asimismo, el análisis con la producción verbal recogida en las observaciones.La implementación del programa se realizó en Visual Basic, lo que permite trabajar en un entorno multitarea como es el entorno windows, con la consiguiente facilidad que esto supone en el uso de este software. Las opciones, en cuanto al tipo de datos se refiere, son junto a los Formatos de Campo, propuestos por Hall (1963), Lindzey (1968), Hutt y Hutt (1974) y Anguera (1979); la tipología de datos propuesta por Bakeman y Quera (1995), a saber: Event Sequential Data (ESD) o Secuencias de Eventos, State Sequential Data (SSD) o Secuencias de Estados, Time Event Sequential Data o Secuencias de Eventos con duración e Interval Sequential Data o Secuencias de Intervalo.
El programa permite recoger y analizar la producción verbal, para lo que realiza un cálculo tanto del número de letras como de las palabras que intervienen en la emisión verbal, además lleva a cabo una estimación de la longitud media de enunciados. Puede, también, etiquetar parte o cada una de las palabras o grupos de ellas, de acuerdo al tipo de estudio que se esté llevando a cabo o al modelo teórico que subyace a la investigación. Realiza un estudio de la frecuencia de las palabras en función del contexto donde se encuentran. El programa genera un fichero en códigos ASCII independiente para el texto (o los resultados de los análisis de la producción verbal), de tal forma que éste puede ser recogido en un procesador de texto o en una tarjeta de sonido que reproduzca la emisión, en el caso del texto.
2. Estructura funcional del programa
Para la construcción del programa se eligió un lenguaje de tipo Visual Tools, concretamente el Visual Basic versión 3.0, que soluciona las necesidades de interface de usuario por el empleo del modo gráfico y la facilidad del lenguaje en el entorno windows, permitiendo así una economía en términos de tiempo en la creación y el diseño de pantallas.El entorno de programación, en el diseño de esta aplicación, se ha estructurado a través de la utilización de ficheros y el intercambio de información entre ventanas. Los ficheros se han organizado de forma secuencial y para el registro se han usado códigos ASCII. Las entradas y salidas de fichero se producen línea a línea, para lo cual se han usado las técnicas Print y Line Input. La selección de ficheros y de identificadores de ficheros (handles) se realiza de forma automática en el interior del programa. Las salidas se archivan en ficheros con extensiones que hacen referencia a la tipología de datos utilizados (*.eve, *.est, *.int, *.mix, *.fam; para eventos, estados, intervalos, eventos con duración y formatos de campo respectivamente). Estos ficheros pueden ser abiertos desde cualquier procesador de textos que importe ficheros en códigos ASCII, debiendo ser respetado el formato de grabación para que sea reconocido por el propio programa. A pesar de que los ficheros generados en función de la tipología de datos tienen extensiones distintas, mantienen partes comunes que permiten el intercambio entre los distintos tipos de observación y/o de datos (sujetos, códigos, observaciones...).
El intercambio de información es necesario para la gestión del programa y está basado en colocar la información en listas (sean éstas desplegables o no) para su fácil acceso. Al cargar una ventana se establecen referencias a estas listas, de tal manera que la información siempre está disponible desde cualquier otra ventana añadiendo un prefijo que la referencie.
La utilización de la técnica Drag-Drop permite eliminar entradas en los códigos y/o sujetos, que no obstante permanecen en memoria, pudiendo, en caso de equivocación, volver atrás y recuperar aquello que fue borrado.
El programa tiene una estructura de desarrollo Top-Dow modular que permite la optimización tanto de la organización, como del control del flujo así como la facilidad en la localización de problemas.
3. Opciones de trabajo
La concepción del programa (Hernández Mendo, 1996b) se ha realizado pensando en la facilidad de uso, permitiendo ser utilizado en cualquier tipo de situación y con cualquier tipo de dato. De aquí que la pantalla inicial al entrar en el programa nos sitúe, por defecto, en Codificación en Soporte Magnético, una de las dos posibles (Codificación en Soporte Magnético y Codificación in situ). Lógicamente, siempre tenemos la opción de elegir entre cualquiera de las dos. Las opciones que aparecen en esta primera pantalla son: Acerca de, Opciones, Idioma (Language), Salir , un menú desplegable en la parte izquierda de la pantalla y en la zona inferior izquierda un icono.
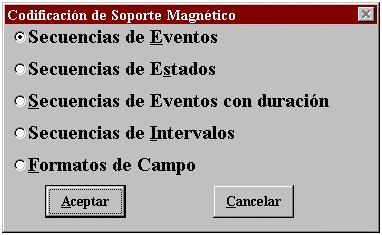
Gráfico Nº 1En la primera de ellas, Acerca de, aparecen los nombres de los autores2 . En Opciones, se recoge los dos tipos de situaciones donde se van a llevar a cabo las sesiones de observación, la opción de Codificación in situ, aparece recogida también en un icono en la parte inferior izquierda de la pantalla. En la opción Idioma permite cambiar el idioma de presentación del programa, del español al inglés o viceversa. Con la opción Salir el programa permite abandonar y regresar al entorno windows.
En la ventana abierta al entrar en el programa (ver gráfico nº1), que pertenece a la opción Codificación en Soporte Magnético (esta opción se puede cambiar en el menú desplegable en Opciones o bien picando con el ratón en el icono que está situado en la zona inferior izquierda de la pantalla), aparecen los tipos de datos con los que podemos trabajar, a saber: Secuencias de Eventos, Secuencias de Estados, Secuencias de Eventos con duración, Secuencias de Intervalos y Formatos de Campo.
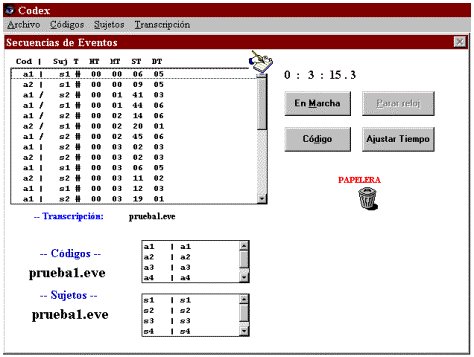
Gráfico Nº 2Al escoger la opción Secuencia de Eventos y picar con el ratón en el botón de Aceptar, se abre una pantalla (ver gráfico nº2), en la que junto a la barra de estado (con las opciones Archivo, Códigos, Sujetos, Transcripción, Unidades de Medida y Concordancias) podemos delimitar tres zonas en la pantalla.
1. Por lo que respecta a la barra de estado, la opción Archivo permite, junto a funciones clásicas de mantenimiento de ficheros (Nuevo, Abrir, Grabar, Grabar como, Imprimir y Salir), la posibilidad de Importar (datos del programa TRANSCRIPTOR) y Exportar (datos a los programa SDIS-GESQ y OBSERVER).En la opción Descripción permite asignarle un título a la investigación así como la descripción de la misma y sus autores. Con la opción Códigos se puede introducir un código nuevo (a través de Nuevo), Modificar uno ya existente o Cargar una lista de códigos ya existe en otra transcripción3 . Esta estructura aparece también en la opción de Sujetos y en Transcripción, aunque esta última posee una opción mas, Observaciones
. 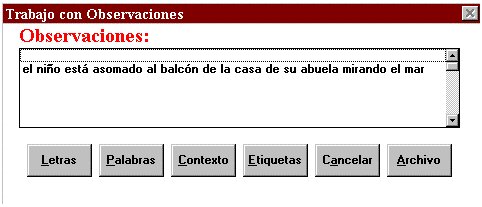
Gráfico Nº 3a. Al picar con el ratón en Observaciones aparece una pantalla con una ventana desplazable donde se recogen todas las observaciones y cinco botones, a saber: Letras, Palabras, Contexto, Etiquetas, Cancelar y Archivo. La opción de Letras permite calcular la frecuencia, la media y el porcentaje de aparición de cada letra o de cada fonema. Por su parte la opción Palabras realiza el mismo cálculo sobre las palabras. En la opción de contexto se abre una persiana desplegable donde se debe elegir la palabra diana sobre la que se desea trabajar, a la derecha de ésta se señalan las palabras por delante y por detrás que se establecerán como contexto, y una vez realizado, en la ventana inferior aparecerán las palabras que forman el contexto (con especificación de cuáles la anteceden y cuáles la preceden). Con la opción de etiquetas podremos asignar un rotulo a cualquier conjunto de letras o palabras, y dependiendo de este etiquetado podremos obtener información sobre la longitud media de enunciados y sobre el número de morfemas. En la opción de Archivo, al picar con el ratón se abre una ventana con opciones sobre el intercambio de datos (Archivar, Imprimir y Cargar), la asignación del nombre del fichero y el contenido del mismo (Observaciones y Resultados).
2. Al escoger la opción Unidades de Medida, se abre un menú desplegable donde aparecen las opciones Frecuencia, Lapso y Tasa. Al picar en Frecuencia se abre una pantalla donde aparecen las frecuencias absolutas, las relativas, las frecuencias de transición y las frecuencias relativas de transición. El retardo para el cálculo de estas últimas se realiza en un drag-drop situado en la parte superior. Tanto para el Lapso como para la Tasa se abren unas ventanas donde aparecen los resultados.
3. En la opción Concordancias se abre un menú donde aparecen las siguientes opciones Coeficiente Pi, Coeficiente con tiempo y Coeficiente Lambda. Al escoger cualquiera de ellos se abre una ventana inicial donde se pide indicar el fichero con el que quiere realizar la comparación. Realizado esto se abre una segunda ventana donde aparecen los resultados.
4. La primera de las zonas delimitadas en la pantalla de codificación de eventos (ver gráfico nº2), es la correspondiente al registro de la transcripción que está situada a la izquierda de la pantalla. En esta pantalla se recogen por este orden: el código, el sujeto y el tiempo (con expresión de horas, minutos, segundos y centésimas de segundos). En la esquina superior derecha de esta ventana aparece un icono (una mano escribiendo) que al picar sobre él, se abre, en la zona inferior derecha, una ventana donde aparecen las observaciones recogidas con expresión del código y el sujeto con el que están asociadas.
5. La segunda de las zonas, situada en la parte superior derecha de la pantalla (ver gráfico nº2), aparece -en la parte alta- el tiempo de transcripción con expresión de horas, minutos, segundos y centésimas de segundo. Por debajo se sitúan cuatro botones: En Marcha, pone en marcha el reloj de la transcripción; Parar reloj, detiene el reloj sin necesidad de realizar ninguna codificación; Ajustar Tiempo, permite ajustar el tiempo del reloj; Código, detiene el reloj y lleva a cabo un registro del evento producido, al picar con el ratón en este botón se abre una ventana (ver gráfico nº4) que muestra:
Gráfico Nº 4En la parte superior, ambos lados, situados los eventos y sujetos definidos. En la zona media aparece un campo para registrar la producción verbal emitida por el sujeto, o bien anotaciones al margen. En la zona inferior aparece el tiempo de observación con expresión de todos los rangos y, finalmente, debajo, dos botones, Aceptar y Cancelar.
6. En la zona media de la pantalla de eventos (ver gráfico nº2) aparece un icono (en color rojo representando un contenedor) que es fruto de la técnica Drag-Drop mediante la cual el programa permite eliminar entradas en los códigos y/o sujetos, que, no obstante, permanecen en memoria, pudiendo, en caso de equivocación, recuperar aquello que fue borrado. Para borrar un código o un sujeto es necesario arrastrarlo con el ratón y llevarlo al contenedor. En el caso de querer recuperarlo, se hace un doble click con el ratón encima de la papelera, abriéndose una ventana donde aparecen lo que hemos borrado, pudiéndolo arrastrar de nuevo hacia la ventana correspondiente.
7. Debajo de este icono hay una zona en blanco, donde se despliega una ventana, con las observaciones y sus correspondientes códigos y sujetos, cuando se pica con el ratón en el icono (de una mano escribiendo), situado en el ángulo superior derecha de la ventana de transcripción (ver gráfico nº2).
8. En la zona inferior izquierda de la pantalla de codificación de eventos (ver gráfico nº2) aparece información relativa a los ficheros empleados por la transcripción, los códigos y los sujetos. Además de esto, en dos ventanas colaterales a esta información permanecen siempre visibles los códigos y los sujetos.
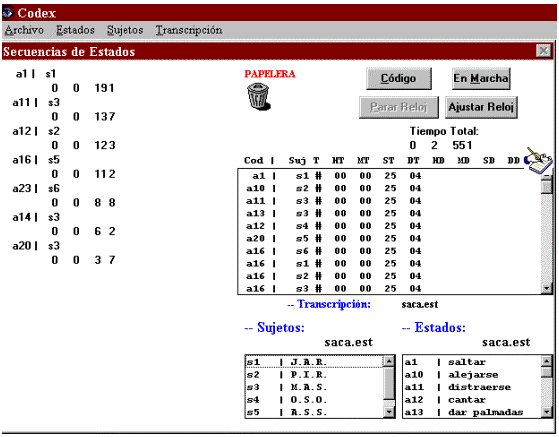
Si en el menú desplegable inicial (ver Gráfico nº1) se escoge la opción Estados, se abre una ventana donde aparecen las mismas opciones que en el caso de los Eventos (ver Gráfico nº2) aunque distribuidos de distinta forma (ver Gráfico nº5). Todas las ventanas (Archivo, Estado, Sujetos, Transcripción, Unidades de Medida y Concordancias) se agrupan en la parte derecha de la pantalla. En la zona izquierda se visualizan los relojes activados por los distintos estados a medida que se van produciendo.
Gráfico Nº 5En la pantalla de transcripción (ver Gráfico nº5) al lado de la indicación del sujeto al que pertenece el estado, aparece un símbolo "+" ó "-" para indicar si es el inicio o final del estado, respectivamente, siguiendo la sintaxis indicada por Bakeman y Quera (1995). La opción de exportar permite exportar ficheros de datos a los programas SDIS-GSEQ (Bakeman y Quera, 1995, 1996), OBSERVER 3.0 (Noldus, 1991) y THEME (Magnuson, 1988).

|
|
|---|---|
|
revista digital ·
Año 5 · Nº 18 |
Buenos Aires, febrero 2000
© 1997/2000 Derechos reservados |
|