
|
|||
|---|---|---|---|
|
|
Nuevas estrategias de análisis aplicadas a la comunicación audiovisual: una experiencia con informativos de televisión |
|
|
|
|
http://www.efdeportes.com/ Revista Digital - Buenos Aires - Año 9 - N° 63 - Agosto de 2003 |
|
|
2 / 2
2.6. Resultados
En el anexo nº 3 aparece el cómputo de las palabras transcritas de las cintas de vídeo correspondientes a los diferentes telediarios con su correspondiente frecuencia de aparición, separadas en dos bloques, las que hacen referencia a los titulares y las que se refieren a la noticia común.
En las siguientes tablas se recoge el cómputo general agrupado por categorías gramaticales (Adjetivos, Adverbios, Sustantivos y Verbos) así como una serie de indicadores (T.T.R., I.R. y E.D.) que han servido para analizar el tipo de expresión que utilizan las diferentes cadenas a la hora de transmitir noticias.
TVE 1
TITULARES

Tabla 2. Cómputo general de los titulares de TVE 1TVE 1
NOTICIA

Tabla 3. Cómputo general de la noticia común de TVE 1TVE 2
TITULARES

Tabla 4. Cómputo general de los titulares de TVE 2TVE 2
NOTICIA

Tabla 5. Cómputo general de la noticia común de TVE 2TELE 5
TITULARES

Tabla 6. Cómputo general de los titulares de Tele 5TELE 5
NOTICIA

Tabla 7. Cómputo general de la noticia común de Tele 5CANAL +
TITULARES

Tabla 8. Cómputo general de los titulares de Canal +CANAL +
NOTICIA

Tabla 9. Cómputo general de la noticia común de Canal +ANTENA 3
TITULARES

Tabla 10. Cómputo general de los titulares de Antena 3ANTENA 3
NOTICIA

Tabla 11. Cómputo general de la noticia común de Antena 3A continuación aparecen unas tablas en las que se recoge una información global y comparativa por cadenas televisivas de los indicadores reveladores del estilo de discurso así como el cómputo general de las diferentes categorías gramaticales y unidades textuales.
Para una mejor lectura de las tablas se han destacado los valores mayores en negrita y los menores en cursiva
Titulares
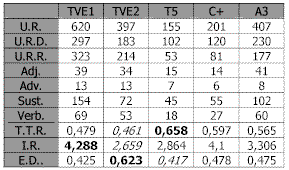
Tabla 12. Información global de los titulares por cadenasComo puede apreciarse en la tabla anterior, y con referencia a los titulares, la cadena que mayor variedad o riqueza de vocabulario posee es Tele 5 (TTR = 0,658), seguida de Canal Plus, Antena 3, TVE1 y TVE2. Con respecto al estilo del discurso mientras que Tele 5, Antena 3, TVE1 y Canal plus utilizan un estilo descriptivo, TVE2, utiliza un estilo mucho más dinámico.
Esto mismo puede apreciarse en la siguiente gráfica correspondiente a dichos indicadores (TTR y ED).
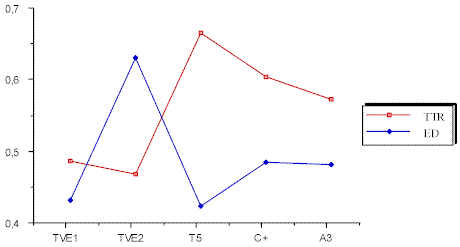
Gráfica 1. Indicadores TTR, ED de Titulares por cadenaCon respecto al indicador de redundancia la cadena que destaca es TVE1 (I R = 4,288), seguida de Canal Plus, Antena 3, Tele 5 y finalmente TVE2 como puede apreciarse en la siguiente gráfica.
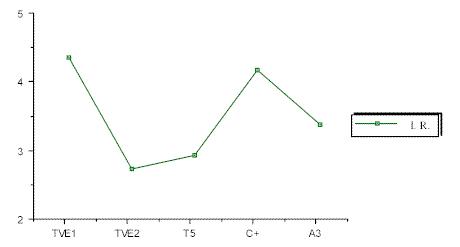
Gráfica 2. Indicador IR de Titulares por cadena
Noticia
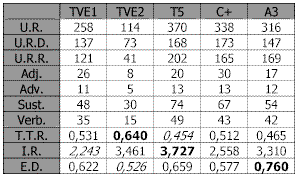
Tabla 13. Información global de la noticia común por cadenaComo puede apreciarse en la tabla anterior, y con referencia a la noticia común analizada, la cadena que mayor variedad o riqueza de vocabulario posee es TVE2, seguida de TVE1, Canal Plus, Antena 3 y Tele 5. Con respecto al estilo del discurso mientras que Antena 3, Tele 5 y TVE1 utilizan un estilo dinámico, Canal plus y TVE2, utilizan un estilo mucho más descriptivo.
Esto mismo puede apreciarse en la siguiente gráfica correspondiente a dichos índices (TTR y ED) de la noticia común.
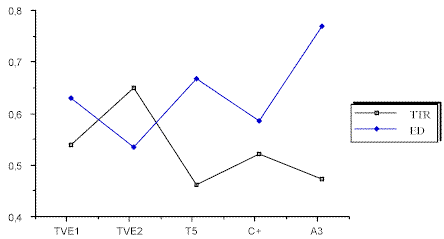
Gráfica 3. Indicadores TTR, ED de noticia común por cadenaCon respecto al indicador de redundancia la cadena que destaca es Tele 5, seguida de TVE2, Antena 3, Canal Plus y finalmente TVE1 como se aprecia en la gráfica siguiente.
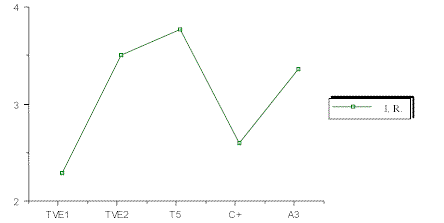
Gráfica 4. Indicadores IR de noticia común por cadenaPosteriormente se realizó un análisis descriptivo para ver el peso relativo de cada categoría gramatical con cada una de las cadenas. La frecuencia de cada una de las categorías gramaticales se ha transformado en la tabla siguiente en porcentajes para facilitar su comprensión, y a partir de las proporciones correspondientes se ha calculado el coeficiente de variación (C.V.) de cada categoría gramatical, tanto de los titulares como de la noticia común. El C. V. es un estadístico de variabilidad que permite comparar distribuciones con diferente media; de esta forma, se hace posible determinar dónde existe mayor dispersión, esto es, en qué categoría gramatical hay mayores diferencias entre las diversas cadenas.
Titulares
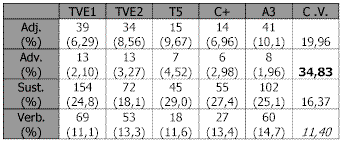
Tabla 14. Análisis descriptivo y Coeficiente de Variación (CV) de los titularesComo se observa en la tabla anterior, en los titulares la mayor dispersión entre las diversas cadenas se da en la categoría "adverbios" (C. V. = 34,83) y la menor en la categoría "verbos" (C. V. = 11,40).
Noticia
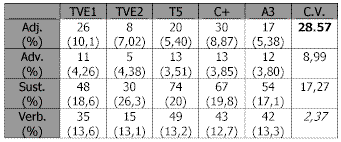
Tabla 15. Análisis descriptivo y Coeficiente de Variación (CV) de la noticia comúnLa tabla anterior, que contiene datos relativos a la "noticia", muestra la mayor dispersión entre las diversas cadenas en la categoría "adjetivos" (C. V. = 28,57) y la menor en la categoría "verbos" (C. V. = 2,37).
A continuación se realizó un análisis exploratorio de todo el material (titulares y noticias) para ver el peso relativo de cada noticia con respecto al global en función del tiempo como puede apreciarse en la siguiente tabla.
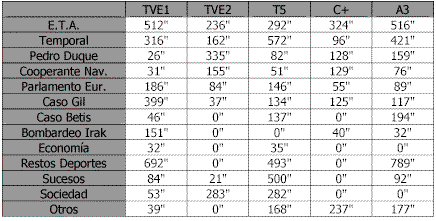
Tabla 16. Análisis exploratorio duración de noticias por cadenasLa matriz de correlaciones correspondiente a los tiempos de duración de las noticias según las cadenas queda como sigue:

Tabla 17. Matriz de correlacionesEn negrita se han indicado las correlaciones más altas. Como se observa en la matriz de correlaciones, la relación directa más pronunciada en tiempos dedicados a cada noticia se produce entre TVE 1 y A3. A3 y TELE 5 muestran también una correlación directa. También destaca el valor de la correlación entre TELE 5 y TVE1.
Con los datos de la tabla anterior se realizó un análisis de varianza de muestras independientes para observar posibles diferencias de los promedios de duración de las noticias en función de las diversas cadenas de televisión. Los resultados de este ANOVA se muestran en el cuadro siguiente:

Tabla 18. Análisis de Varianza duración de las noticias por cadenas de televisiónComo p = 0,0005, eso significa que no es aceptable afirmar que los tiempos de duración de las noticias sean similares, esto es, el promedio en tiempo de las noticias en cada cadena es diferente.
Para poder determinar si además cada noticia es diferente o no según el "tratamiento" que le da cada cadena, es indispensable realizar un análisis de medidas repetidas, un análisis multivariante de la varianza (MANOVA) de muestras relacionadas, tomando como sujetos las diferentes noticias y como tratamientos las cadenas, tal y como aparecen reflejadas en la tabla anterior. El resultado de este MANOVA de medidas repetidas se recoge en el cuadro siguiente:

Tabla 19. Análisis de Varianza de medidas repetidas (MANOVA): duración de las noticias por cadenas de televisiónComo p = 0,068, no se puede afirmar que las cadenas de televisión den un tratamiento diferenciado a las noticias en cuanto al tiempo que le dedican.
El mismo resultado se obtiene, lógicamente, si se aplican las correspondientes pruebas no paramétricas (Q de Kendall y F de Friedman) para muestras relacionadas, como se ve en los cuadros siguientes:

Tabla 20. Prueba no paramétrica F de Friedman

Tabla 21. Prueba no paramétrica Coeficiente de Concordancia de KendallPara estudiar las relaciones y determinar posibles patrones característicos de las cadenas en función de las categorías gramaticales y unidades de registro empleadas se emplearon diversos análisis log-lineales aplicados a los titulares de las diferentes cadenas y a la noticia común seleccionada (ver anexo nº 4).
El procedimiento general utilizado en el análisis log-lineal fue el siguiente: en primer lugar se construía el modelo jerárquico saturado y a partir de él se iba comprobando el ajuste de los diferentes modelos "paso a paso" (stepwise) por el procedimiento backward1 (eliminando parámetros de forma sucesiva), siempre guiando la construcción de los modelos a partir de la prueba de los efectos k y del estudio de las asociaciones parciales2 . La evaluación y selección de los modelos que explican las relaciones entre variables se realizó basándonos en los siguientes criterios: en primer lugar el criterio de significación estadística (desestimando los modelos que no se ajustaban a los datos de forma significativa), en segundo lugar el criterio de interpretación sustantiva y en tercer lugar el criterio de parsimonia (esto es, a igual significación estadística y posible interpretación sustantiva eligiendo el que posee un menor número de variables y efectos intervinientes).
Para los Titulares se comenzó construyendo el modelo jerárquico saturado (modelo I) con las variables (CADENA), categoría gramatical (CATGRAL) y unidades de registro (UNIREG). A partir de este modelo que ajustaba perfectamente (LR c2 = 0 y c2 = 0), aunque lógicamente incluyendo demasiados efectos redundantes, se realizó la prueba de los efectos k y se estudiaron las asociaciones parciales. Este proceso puede verse de forma resumida en las siguientes tablas.

Tabla 22. Prueba de los efectos k de los titularesEn la tabla 22 se observa cómo parecen suficientes los efectos de orden 2 (p = 0.00005) y no relevantes los de orden superior (p = 0.6447).

Tabla 23. Asociaciones parciales de los titularesEn la prueba de las asociaciones parciales (tabla 23) se observa cómo no todos los niveles de orden 2, son imprescindibles de cara a la construcción del modelo (interacción de orden 2 entre CADENA y CATGRAL con p > 0.05).
En la siguiente tabla se incluyen los modelos jerárquicos construidos a partir de la información obtenida en la prueba de los efectos k y en las asociaciones parciales. Para economizar espacio en la formulación de los modelos se ha utilizado la nomenclatura de ajuste marginal de Knoke y Burke (1980).

Tabla 24. Modelos log-lineales jerárquicos de los titularesComo se observa en la tabla anterior ningún modelo se ajustaba mínimamente (p < 0,000), por lo que se optó por eliminar la variable UNIREG. Repitiendo el procedimiento sin dicha variable se obtuvieron, para el modelo saturado correspondiente (modelo VII), la prueba de los efectos k y las asociaciones parciales.

Tabla 25. Prueba de los efectos k de los titulares (sin UNIREG)

Tabla 26. Asociaciones parciales de los titulares (sin UNIREG)En la siguiente tabla aparecen los modelos construidos a partir de la información anterior.

Tabla 27. Modelos log-lineales jerárquicos de los titulares (sin UNIREG)Como se observa en la tabla anterior, el único modelo que se ajusta es el de independencia (modelo VIII), con p = 0.259, sin tener para nada en cuenta la variable UNIREG. Otros modelos construidos, dejando a un lado otras variables, obtuvieron una significación estadística no aceptable (p = 0.05).
La expresión completa que resumen este modelo log-lineal jerárquico de independencia (sin UNIREG) es la siguiente:
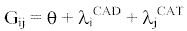
Este modelo explica suficientemente las relaciones entre las diferentes cadenas televisivas y las categorías gramaticales sin necesidad de contar para nada con las unidades de registro y sin ningún efecto de interacción (modelo de independencia).
Una vez seleccionado el modelo VIII se estimaron los parámetros del mismo con el objeto de conocer los diferentes valores posibles de la ecuación y poder realizar predicciones. En el siguiente cuadro aparecen todos los parámetros estimados no redundantes.

Tabla 28. Estimación de los parámetros no redundantes de los titularesPara el análisis log-lineal de la noticia común analizada, se comenzó construyendo el modelo jerárquico saturado (modelo XI) con las variables CADENA, categoría gramatical (CATGRAL) y unidades de registro (UNIREG). A partir de este modelo que ajustaba perfectamente (LR?2 = 0 y ?2 = 0), se realizó la prueba de los efectos k y se estudiaron las asociaciones parciales. Este proceso puede verse de forma resumida en las siguientes tablas.

Tabla 29. Prueba de los efectos k de la noticia comúnEn la tabla 29 se observa cómo parecen suficientes los efectos de orden 2 (p = 0.00005) y no relevantes los de orden superior (p = 0.5934).

Tabla 30. Asociaciones parciales de la noticia comúnEn la siguiente tabla se incluyen los modelos jerárquicos construidos a partir de la información obtenida en la prueba de los efectos k y en las asociaciones parciales.
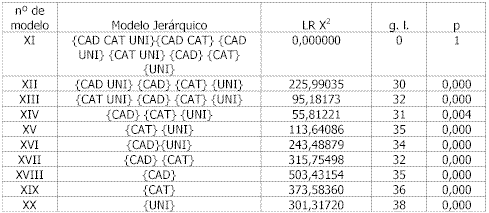
Tabla 31. Modelos log-lineales jerárquicos de la noticia comúnComo se observa en la tabla anterior ningún modelo se ajustaba mínimamente (p < 0,000), por lo que se optó por eliminar la variable UNIREG. Repitiendo el procedimiento sin dicha variable se obtuvieron, para el modelo saturado correspondiente (modelo XXI), la prueba de los efectos k y las asociaciones parciales.

Tabla 32. Prueba de los efectos k de la noticia común (sin UNIREG)

Tabla 33. Asociaciones parciales de la noticia común (sin UNIREG)
En la siguiente tabla aparecen los modelos construidos a partir de la información anterior.

Tabla 34. Modelos log-lineales jerárquicos de la noticia común (sin UNIREG)Como se observa en la tabla nº 34, el único modelo que se ajusta es el de independencia (modelo XXII), con p = 0.796, sin tener para nada en cuenta la variable UNIREG. Otros modelos construidos dejando a un lado otras variables nunca obtuvieron una significación estadística aceptable (p = 0.05).
La expresión completa que resumen este modelo log-lineal jerárquico de independencia (sin UNIREG) es la siguiente:
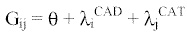
Este modelo explica suficientemente las relaciones entre las diferentes cadenas televisivas y las categorías gramaticales sin necesidad de contar para nada con las unidades de registro y sin ningún efecto de interacción (modelo de independencia).
Una vez seleccionado el modelo XXII se estimaron los parámetros del mismo con el objeto de conocer los diferentes valores posibles de la ecuación y poder realizar predicciones. En el siguiente cuadro aparecen todos los parámetros estimados no redundantes.

Tabla 35. Estimación de los parámetros no redundantes de la noticia comúnTambién se ha realizado un análisis de generalizabilidad con el objetivo de investigar si las condiciones de medición de nuestro estudio comparadas con las fuentes de variabilidad inciden sobre el proceso de medida.
Posteriormente y teniendo en cuenta los datos reales del análisis de generalizabilidad, se realizó un estudio de decisión para, en una investigación futura, mejorar las condiciones de medición y con ello aumentar la generalizabilidad de los datos.
Tanto para el estudio de generalizabilidad como para la optimización de los datos se ha utilizado el programa informático G.T. v. 2.0 E. de Pierre Ysewijn (1996).
El procedimiento general utilizado fue el siguiente: en primer lugar se identificó el tipo de diseño con el que se cuenta, que en este caso es un diseño simétrico de cuatro facetas T x C x G x U, (estructuración de los telediarios, cadenas, categorías gramaticales y unidades de registro), bajo la suposición de que todos los componentes son variables aleatorias distribuidas al azar.
El programa realiza un análisis de varianza, en donde se identifican las fuentes de variación, se calculan las medias cuadráticas y se estiman los componentes de varianza de cada efecto y de sus combinaciones, como se puede comprobar en la siguiente tabla (y de forma desarrollada en el anexo nº 5).
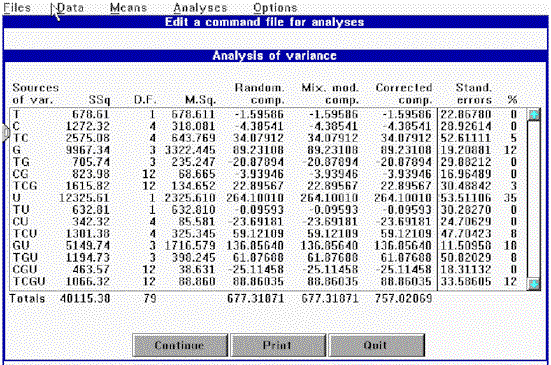
Tabla 36. Análisis de varianza de las fuentes de variaciónEl siguiente diagrama de Venn representa todas las fuentes de variación junto con la fórmula para obtener las medias cuadráticas correspondientes.
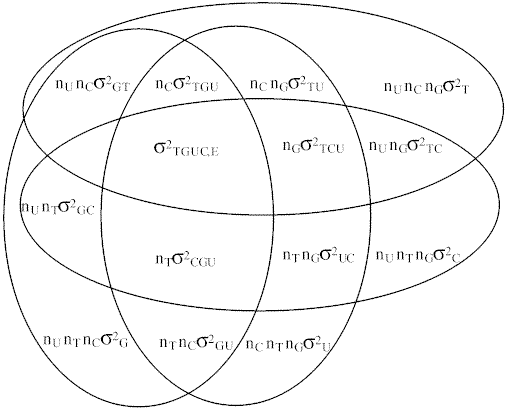
Diagrama 1. Representación de las medias cuadráticasComo se observa del análisis de varianza (v. tabla 36), el factor de más relevancia es unidades de registro (U) con un 35% de variabilidad seguido de la interacción de ese factor con las categorías gramaticales (UG) con un 18% de variabilidad, en tercer lugar nos encontramos con las categorías gramaticales (G) con un 12%.
A continuación se realiza el análisis de generalizabilidad para lo cual se seleccionan los diferentes planes de medida en función de cómo se considere a las facetas; es decir, de generalización o de diferenciación.
Teniendo en cuenta esto último tendremos, en nuestro caso, catorce planes de medida como puede comprobarse en el anexo nº 5 y a modo de resumen en las dos siguientes tablas.
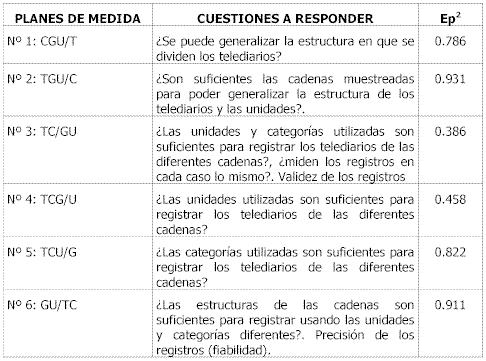
Tabla 37. Planes de medida y coeficientes de generalizabilidad IEl plan nº 1, sitúa como faceta de diferenciación a los factores cadenas de televisión (C), a las categorías gramaticales (G) y a las unidades de registro (U) mientras que la estructura de los telediarios (T) se coloca como faceta de generalización. La cuestión que se plantea es si la estructuración de los telediarios que se ha realizado (titulares y noticia) es suficiente para poder generalizar los datos. Como el coeficiente de correlación es aceptable (0.786), se puede afirmar que sí. De todas maneras, en la optimización de los datos correspondiente a este plan, habría que duplicar el número de observaciones para alcanzar un coeficiente de generalizabilidad de 0.88 (véase el anexo nº 5).
El plan de medida nº 2, diferencia a la estructuración de los telediarios (T), las categorías gramaticales (G) y a las unidades de registro (U) de las cadenas de televisión (C) que en este plan conforman la faceta de generalización. Se respondería a la cuestión de si son suficientes las cadenas para poder generalizar la estructura de los telediarios. Teniendo en cuenta que el coeficiente de generalizabilidad es de 0.931, se puede afirmar con bastante seguridad la cuestión que genera este plan de medida.
El tercer plan sitúa como objeto de estudio a la estructuración de los telediarios (T) y a las cadenas de televisión (C) la cuestión que se plantea es si las unidades y categorías utilizadas son suficientes para registrar los telediarios de las diferentes cadenas, en este plan aparecen las categorías gramaticales (G) y las unidades de registro como faceta de generalización. Con un coeficiente de generalizabilidad de 0.386, no puede afirmarse que las unidades y categorías utilizadas en este estudio sean suficientes para registrar los telediarios, por lo tanto nos remitiríamos a la optimización de dicho plan y nos daríamos cuenta que hacen falta 960 observaciones para que dicho coeficiente suba hasta 0.785, por lo tanto no sería conveniente realizar dicho plan de investigación debido a la poca rentabilidad entre el coste/beneficio (véase el anexo nº 5).
El plan de medida nº 4 diferencia a la estructuración de los telediarios (T), a las cadenas de televisión (C) y a las categorías gramaticales (G) que conforman la faceta de diferenciación de este plan de medida, de las unidades de registro (U) que se colocan como faceta de generalización, respondiendo a la siguiente cuestión ¿las unidades utilizadas son suficientes para registrar los telediarios de las cadenas? Con un coeficiente de generalización de 0.458, tendríamos que responder de forma negativa, pero remitiéndonos al plan de optimización, se observa que triplicando el número de observaciones tendríamos un coeficiente de generalizabilidad algo más que aceptable, 0.717 (véase el anexo nº 5).
El plan de medida nº 5, sitúa como faceta de diferenciación a la estructuración de los telediarios (T), a las cadenas de televisión (C) y a las unidades de registro (U), siendo las categorías gramaticales (G) las que conforman la faceta de generalización. Este plan se plantea si las categorías utilizadas son suficientes para registrar los telediarios de las diferentes cadenas. Teniendo en cuenta que el coeficiente de generalizabilidad es de 0.822, se puede afirmar con bastante seguridad la cuestión que se plantea este plan de medida.
El plan de medida nº 6, sitúa como faceta de diferenciación a las categorías gramaticales (G) y a las unidades de registro (U), siendo la estructuración de los telediarios (T) y las cadenas de televisión (C), las facetas de generalización, en esta ocasión nos planteamos si las estructuras de las cadenas son suficientes para registrar usando las unidades y categorías diferentes. En definitiva sería hablar de precisión de los registros (fiabilidad). En este plan se obtiene un coeficiente de generalizabilidad de 0.911, con lo cual podríamos afirmar que sí.
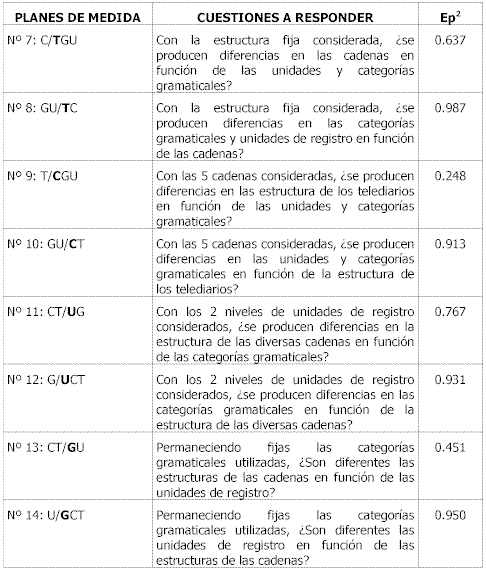
Tabla 38. Planes de medida y coeficientes de generalizabilidad II3A partir del plan nº 7 el análisis de varianza cambia al considerarse una de las facetas fija aunque permanece el mismo orden de factores que en los anteriores planes, es decir, el factor de más relevancia sigue siendo unidades de registro (U), seguido de la interacción de ese factor con las categorías gramaticales (UG) y en tercer lugar nos encontramos con las categorías gramaticales (G) (ver anexo nº 5).
El plan de medida nº 7 sitúa como faceta de diferenciación a las cadenas de televisión (C) mientras que la estructuración de los telediarios (T), las categorías gramaticales (G) y las unidades de registro (U) constituirían la faceta de generalización, (T) como faceta fija, siendo las otras tres infinitas. La cuestión que se plantea es si con la estructura fija considerada se producen diferencias en las cadenas en función de las unidades y categorías gramaticales utilizadas. Con un coeficiente de generalizabilidad de 0.637, no puede afirmarse con seguridad la cuestión que se nos planteaba por lo tanto nos remitiríamos a la optimización de dicho plan y nos daríamos cuenta que hacen falta 360 observaciones para que dicho coeficiente suba hasta 0.821, por lo tanto no sería conveniente realizar dicho plan de investigación debido a la poca rentabilidad entre el coste/beneficio (véase el anexo nº 5)
El octavo plan de medida, sitúa como objeto de estudio las categorías gramaticales (G) y las unidades de registro (U), mientras que la estructuración de los telediarios (T) y las cadenas de televisión (C) se colocan como facetas de generalización, (T) como faceta fija y las demás como infinitas. La cuestión planteada es la siguiente: si con la estructura fija considerada, se producen diferencias en las categorías gramaticales y unidades de registro en función de las cadenas. Teniendo en cuenta que el coeficiente de generalizabilidad es de 0.987, se puede afirmar con bastante seguridad la cuestión que genera este plan de medida.
El plan de medida nº 9 sitúa como faceta de diferenciación a la estructuración de los telediarios (T), mientras que las cadenas (C), las categorías gramaticales (G) y las unidades de registro (U) constituirían la faceta de generalización, (T) como faceta fija, siendo las otras tres infinitas. La cuestión que se plantea es si se producen diferencias en las estructura de los telediarios en función de las unidades y categorías gramaticales con las 5 cadenas consideradas. Con un coeficiente de generalizabilidad de 0.248, no puede afirmarse la cuestión que se nos plantea, por lo tanto nos remitiríamos a la optimización de dicho plan tendríamos que realizar más de 700 observaciones para obtener un coeficiente de generalizabilidad medio razonable. Ni que decir tiene la poca rentabilidad de llevar a cabo dicho plan.
El plan de medida nº 10, sitúa como objeto de estudio las categorías gramaticales (G) y las unidades de registro (U), mientras que las cadenas de televisión (C) y la estructuración de los telediarios (T) y se colocan como facetas de generalización, (C) como faceta fija y las demás como infinitas. La cuestión planteada es la siguiente. si con la estructura fija considerada, se producen diferencias en las unidades y categorías gramaticales en función de la estructura de los telediarios. Teniendo en cuenta que el coeficiente de generalizabilidad es de 0.913, se puede afirmar con bastante seguridad la cuestión que genera este plan de medida.
El plan de medida nº 11, manteniendo en la faceta de generalización a las unidades de registro (U) como faceta fija y a las categorías gramaticales (G), sitúa como objeto de estudio a las cadenas de televisión (C) y la estructuración de los telediarios (T), la cuestión que se plantea en este plan es la siguiente: si con los 2 niveles de unidades de registro considerados, se producen diferencias en la estructura de las diversas cadenas en función de las categorías gramaticales. Teniendo en cuenta que el coeficiente de generalizabilidad es de 0.767, se puede afirmar que sí. De todas maneras, en la optimización de los datos correspondiente a este plan, se puede observar que para alcanzar un coeficiente de generalizabilidad de 0.804 habría que aumentar el número de observaciones tan sólo en 20 más. (véase el anexo nº 5).
El plan de medida nº 12, sitúa como objeto de estudio las categorías gramaticales (G) mientras que las unidades de registro (U), las cadenas de televisión (C) y la estructuración de los telediarios (T) se colocan como faceta de generalización, (U) como faceta fija y las demás como infinitas. La cuestión planteada es si con los 2 niveles de unidades de registro considerados, se producen diferencias en las categorías gramaticales en función de la estructura de las diversas cadenas. Teniendo en cuenta que el coeficiente de generalizabilidad es de 0.931, se puede afirmar con bastante seguridad la cuestión que genera este plan de medida.
El plan de medida nº 13, manteniendo en la faceta de generalización a las unidades de registro (U) y a las categorías gramaticales (G) como faceta fija, sitúa como objeto de estudio a las cadenas de televisión (C) y la estructuración de los telediarios (T), la cuestión que se plantea en este plan es: si permaneciendo fijas las categorías gramaticales utilizadas, son diferentes las estructuras de las cadenas en función de las unidades de registro. Teniendo en cuenta que el coeficiente de generalizabilidad es de 0.451 tendríamos que responder de forma negativa y nos remitiríamos al plan de optimización, en el que se observa que triplicando el número de observaciones tendríamos un coeficiente de generalizabilidad algo más que aceptable, 0.712 (véase el anexo nº 5).
En el plan de medida nº 14, se sitúa como objeto de estudio las unidades de registro (U), siendo las categorías gramaticales (G), las cadenas de televisión (C) y la estructuración de los telediarios (T) la faceta de generalización, (G) como faceta fija y las demás como infinitas. La cuestión planteada es si permaneciendo fijas las categorías gramaticales utilizadas, son diferentes las unidades de registro en función de las estructuras de las cadenas. Teniendo en cuenta que el coeficiente de generalizabilidad es de 0.950, se puede afirmar con bastante seguridad la cuestión que genera este plan de medida.
3. DiscusiónLos indicadores de la expresión del análisis de contenido realizado muestran algunas diferencias interesantes entre las cadenas de televisión consideradas.
Con respecto a los titulares, de las cadenas privadas destaca positivamente Tele 5. Posee la mayor valoración en riqueza lingüística, emplea pocos términos redundantes y utiliza un lenguaje bastante dinámico en la presentación de las noticias. Las otras dos cadenas privadas, A3 y C+, mantienen una elevada riqueza del lenguaje empleado, si bien utilizan un lenguaje más redundante y descriptivo.
En las cadenas públicas consideradas los titulares se presentan como dos fórmulas casi opuestas. Coinciden en emplear una riqueza lingüística muy limitada, pero se comportan de manera muy diferente en los otros dos índices. Mientras que TVE 1 emplea muchos términos redundantes y un estilo del discurso descriptivo, TVE 2 es la menos redundante y utiliza el estilo más dinámico de todo el conjunto. Esto podría ser debido a una política interna del ente público consistente en ofrecer dos fórmulas diferentes de presentación de las noticias con la intención de abarcar un mayor abanico de demanda informativa.
Los comportamientos de las cadenas cuando se analiza el desarrollo de una noticia concreta no siguen la misma pauta que cuando se refieren a titulares. La noticia común elegida, como ya se indicó anteriormente fue la del "caso Gil", por el enorme impacto de actualidad que produjo.
Ahora quien destaca positivamente, entre las cadenas privadas, es C+. Emplea un lenguaje rico, poco redundante y un estilo dinámico. Las otras cadenas privadas coinciden cuando desarrollan una noticia en no emplear demasiada riqueza, utilizan términos muy redundantes y un estilo de lenguaje descriptivo. C+ parece dirigirse a un público más elitista o cultivado, que no necesita demasiadas explicaciones para entender correctamente una noticia y que prefieren un desarrollo dinámico de la noticia. Por el contrario, A3 y Tele 5 coinciden en un lenguaje repetitivo para facilitar la comprensión del espectador, no se complican en utilizar demasiados sinónimos y se recrean más en la descripción de los hechos.
Las cadenas públicas consideradas también se muestran de forma diferente a como lo hacían en los titulares. Cuando se trata de desarrollar una noticia concreta, tanto TVE 1 como TVE 2 emplean un lenguaje bastante más rico que antes y un comportamiento opuesto en el uso de términos redundantes. Ahora en el desarrollo de la noticia TVE 1 emplea pocos términos redundantes y TVE 2 bastantes más que en el análisis anterior. Con respecto al estilo del lenguaje ambas cadenas siguen con la misma tendencia, esto es, TVE 1 utiliza un estilo descriptivo y TVE 2 dinámico, tal y como hacían con los titulares.
Cuando se tuvieron en cuenta las categorías gramaticales que conforman los principales indicadores de expresión se observó cómo en los titulares, todas las categorías en las diferentes cadenas tenían una frecuencia de aparición muy heterogénea (como nos lo mostraban los coeficientes de variación obtenidos). No deja de ser un hecho paradójico que haya tanta heterogeneidad en unos titulares cuya característica primordial debiera ser precisamente el informar de una forma escueta y directa el contenido esencial de las noticias.
Cuando se consideró al mismo nivel de categorías gramaticales, la misma noticia desarrollada en las diferentes cadenas ("caso Gil") se observó que los adjetivos y los sustantivos tenían un comportamiento muy heterogéneo, mientras que los verbos y los adverbios eran tratados por las diferentes cadenas de una forma homogénea.
Los análisis realizados teniendo en cuenta los tiempos dedicados a cada noticia destacaron algunos hechos de cierta relevancia:
En primer lugar, las correlaciones mostraron cómo existía un grupo de cadenas relacionadas de manera directa. TVE 1, A3 y TELE 5 realizan una similar distribución del tiempo entre los bloques y las noticias, esto es, las noticias con más tiempo dedicado coinciden, otro tanto ocurre con las que menos tiempo disponen. Esa relación es prácticamente nula o no existe entre cualquiera de las tres anteriores y TVE 2 y C+, que poseen unas formas peculiares de distribuir el tiempo a dada noticia.
Cuando se tomaron los datos de forma independiente (muestras no relacionadas) y se realizó el análisis de varianza, se observó cómo el tiempo promedio dedicado a las noticias por cada cadena era significativamente diferente. Esto quiere decir que cada cadena planifica un tiempo medio diferente de desarrollo de las noticias.
Para observar si el tratamiento que a cada noticia le dan las diversas cadenas es similar o diferente, se sometieron los mismos datos a una serie de análisis correspondientes. En ninguna de las pruebas se obtuvieron resultados significativos, por lo que no es posible afirmar que las diversas cadenas realicen un tratamiento diferente (en cuanto al tiempo) de las mismas noticias.
Este fracaso relativo pudiera ser matizado si en un diseño similar de muestras relacionadas se tuvieran en cuenta datos de indicadores de expresión o de categorías gramaticales.
Esto es, con los resultados obtenidos en el análisis de contenido realizado en base a los indicadores de expresión y a la contabilización de las categorías gramaticales en una noticia concreta se ha observado diferencias de bastante relevancia, como se ha comentado al principio de este mismo apartado. Pues bien, si se realizara esto mismo (obtener los indicadores de expresión y contabilizar las categorías gramaticales) en todas las noticias del mismo informativo, o de una muestra representativa de informativos, resulta muy plausible suponer que sí se obtendrían diferencias de tratamiento de las mismas noticias en los diversos informativos.
Con referencia al análisis log-lineal, cabe destacar que tanto para los titulares como para la noticia común elegida, el modelo explicativo que mejor se ajusta a los datos es el de independencia eliminando la variable unidades de registro (UNIREG). Esto significa que para explicar el comportamiento de los datos, no es necesario contar con la variable unidades de registro (UNIREG) ni con ninguna de las interacciones del resto de las variables, sino simplemente con los efectos independientes de las variables categorías gramaticales (CATGRAL) y cadenas (CAD).
Del análisis de generalizabilidad se puede destacar que las cadenas analizadas son suficientes para poder generalizar la estructuración que se ha realizado de los mismos (plan de medida nº 2), además que la división de noticia y titulares realizada en cada una de las cadenas son suficientes para recoger información usando las unidades y categorías, esto es, la precisión y fiabilidad de los registros (plan de medida nº 6).
También es destacable que, teniendo en cuenta la estructura fija considerada, se producen diferencias en las categorías gramaticales y unidades de registro en función de las cadenas como muestra el coeficiente de generalizabilidad del plan de medida nº 8.
Como se observa en el plan de medida nº 10, la estructura fija considerada hace que se produzcan diferencias en las unidades y categorías gramaticales en función de la estructuración que se ha realizado de los telediarios y también, teniendo en cuenta los 2 niveles de unidades de registro considerados, podemos observar que se producen diferencias en las categorías gramaticales en función de la estructura de las diversas cadenas (plan de medida nº 12). Además permaneciendo fijas las categorías gramaticales utilizadas, son diferentes las unidades de registro en función de las estructuras de dichas cadenas. Teniendo en cuenta que el coeficiente de generalizabilidad del plan nº 14 es de 0.950.
Todas estas modestas conclusiones podrían tener mayor representatividad si se realizara una investigación que contemplara, no una emisión de informativos en un día concreto, sino una muestra más amplia que representase más fielmente una temporada televisiva.
Numerosas puertas quedan abiertas a raíz de esta investigación.
El estudio del emisor, en este caso las cadenas televisivas, tratando de precisar, de acuerdo con el contenido de las informaciones emitidas, determinadas características de este último (a qué target se dirige, qué pretende, qué política interna tiene esa cadena,…). ¿Qué intenta comunicar?, es decir precisar las direcciones sucesivas que toma el contenido del mensaje (temas que se tratan, slogans utilizados…).
Estudiar el análisis de la recepción, esto es, analizar a qué tipo de público va dirigida cada cadena según el lenguaje utilizado y la "intencionalidad" de la cadena cuando elige unos términos, y no otros, en el desarrollo de las noticias. Agrupar por campos semánticos y crear categorías para realizar un análisis de contenido en mayor profundidad.
Qué resultados obtienen las cadenas con todas esas estrategias que utiliza. Lo que se pretende es conocer el efecto del mensaje sobre el receptor, así como la influencia de las personalidades o locutores que animan ciertos informativos.
Otra vía de investigación sería analizar la tendencia de la prensa o información televisiva. Esta línea de trabajo podría ser relacionada además con la búsqueda de las audiencias por parte de cadenas.
También es más que posible que si se hubiera realizado la investigación en una época electoral, las diferencias de tratamiento observadas en las noticias de corte político habrían podido verse aumentadas. Sería también digna de estudio la zona geográfica de influencia de los diarios o información políticos y la búsqueda de correlaciones con los resultados electorales
Investigar las prioridades informativas de cada cadena en base al orden de aparición de cada tipo de noticia. Esto unido a un análisis más exhaustivo de los tiempos de duración de las noticias podría ilustrar con mayor claridad las políticas rectoras en las diferentes cadenas.
Notas
Se eligió este procedimiento y no el inverso (forward) -tal como proponen Benedetti y Brown, (1978) y Upton (1978)-, para tener siempre la referencia del modelo saturado (de ajuste perfecto a los datos originales) a la hora de ir eliminando términos de forma sucesiva, de esta forma es posible determinar a partir de qué modelo el ajuste no es bueno.
Tanto la prueba de los efectos k como el estudio de las asociaciones parciales son las técnicas usuales para explorar la relativa importancia de cada parámetro en el modelo. La prueba de los efectos k permite comprobar si los efectos de un orden concreto son o no iguales a cero, y todo ello para poder determinar hasta qué nivel de interacción se debe contar para la construcción del modelo. La asociación parcial evalúa la contribución de los parámetros individuales en la construcción del modelo, esto es, la parte de la varianza explicada por cada uno de los parámetros del modelo (Brown, 1976; Upton, 1978).
Se han señalado en negrita las facetas que se han considerado fijas para la realización de los planes de medida.
Referencias bibliográficas
Albig, W. (1938). The content of radio programs 1925-1935. Social Forces, 16, 338-349.
Allport, G. W. y Fadner, J. M. (1940). The psychology of newspapers: five tentative laws. Public Opinion Quarterly 4, 687-703.
Arnau, J.; Blanco, A. Y Losada, J.L. (1991). Estimación de la precisión de un diseño multivariable de medidas repetidas. Anales de psicología, 7, (1), 85-104.
Baldwind, A. L. (1942). Personality structure analysis: a statistical method for investigating the single personality. J. Abnorm. Soc. Psychol., 37
Bardin, L. (1977). Análisis de Contenido. Madrid: AKAL.
Benedetti, J. K. Y Brown, M. B. (1978). Strategies for the selection of log-linear models. Biometrics, 34.
Berelson, B. (1952). Content Analysis in Communications Research. New York. Free Press
Berelson, B.; Lazarsfeld, P.F. (1948). The Analysis of Communications Content. Chicago and New York: University of Chicago and Columbia University.
Blanco, A.; Losada, J.L. y Anguera, M.T. (1991). Estimación de la precisión en diseños de evaluación ambiental. Evaluación Psicológica, 7, ( 2), 223-257.
Blumler, J.; Katz, E. (1974). The Uses of Mass Communication. Current Perspectives on Gratifications Research. Sage, Beverly Hills.
Bogdan, R.C. y Biklen, S.K. (1982). Qualitative Research for Education. An Introduction to theory and Methods. Boston: Allyn and Bacon,Inc.
Cantril, H. (1940). America faces the war: a study in public opinion. Public Opinion Quarterly, 4, 387-407.
Carro, L. (1993). Posibilidades de WordPerfect 5.1 para el análisis de datos cualitativos. VI Seminario de Modelos de Investigación Educativa.
Cavanaugh, J. W. (1995). Media effects on voters: A panel study of the 1992 presidential election. Lanham, MD, USA: University Press of America.
Cohen, B. C. (1963). The Press and Foreign Policy. Princeton University Press.
Chavez V. y Dorfman L. (1997). Spanish language television news portrayals of youth and violence in California. International Quarterly of Community Health Education, 16(2), 121-138.
Chew, F. (1992). Information needs during viewing of serious and routine news. Journal of Broadcasting and Electronic Media, 36(4), 453-466.
Dorfman, L., Woodruff, K., Chavez, V. y Wallack, L. (1997). Youth and violence on local television news in California. American Journal of Public Health, 87 (8), 1311-1316.
Envisionology (1992). Cvideo. User Guide. San Francisco, CA: Autor
Fenton, F. (1910). The influence of newspaper presentations on the growth of crime and other anti-social activity. American Journal of Sociology, 16, 342-271, 538-564.
Fontcuberta, M. de, Velázquez, T. (1987). La interpretación de la noticia periodística. En Métodos de análisis de la prensa. Encuentros sobre metodología del análisis de la prensa (en torno a El País). Madrid: Casa Velázquez.
George, A. L. (1959). Propaganda Analysis: A Study of Inferences Made from Nazi Propaganda in World War II. Evanston, IL: Row, Peterson.
Gerbner, G., Holsti, O. R., Krippendorff, K., Paisley, W. J. y Stone, P.J. (1969). The Analysis of Communication Content: Developments in Scientific Theories and Computer Techniques. New York: John Willey.
Grawitz, M. (1975). Métodos y técnicas de las ciencias sociales. Barcelona, Hispano Europea.
Hesse-Bier, S. y otros (1991). HyperRESEARCH: A computer program for the analysis of qualitative data with an emphasis on hypothesis testing and multimedia analysis. Qualitative Sociology, 14, 325-348.
Johnson, R. N. (1996). Bad news revisited: The portrayal of violence, conflict and suffering on television news. Peace and Conflict: Journal of peace psychology, 2(3), 201-216.
Katz, E. (1959). Mass Communication Research and the Study of Popular Culture. Studies in Public Communication, 2.
Katz, E., Blumler, J., Gurevitch, M. (1974). Uses of Mass Communication by the Individual. En Blumler, J., Katz, E. (eds.) The Uses of Mass Communication. Current Perspectives on Gratifications Research. Sage, Beverly Hills.
Kepplinger, H. M. y Daschmann, G. (1997). Today's news tomorrow's context: A dynamic model of news processing. Journal of Broadcasting and Electronic Media, 41(4), 548-565.
Knoke, D. y Burke, P. J. (1980). Log-linear Models. Beverly Hills, CA: Sage.
Krippendorff, K. (1990). Metodología de análisis de contenido: Teoría y Práctica. Barcelona: Paidós Ibérica, S.A.
Laswell, H.D. (1938). A provisional classification of symbol data. Psychiatry, 1, 197-204.
Laswell, H.D. (1941). The world attention survey: an exploration of the possibilities of studying attention being given to the United States by newspapers abroad. Public Opinion Quarterly, 5, 3, 456-462.
Lazarsfeld, P. (1940). Radio and the Printed Page. An Introduction to the Study of Radio and Its Role in Communication of Ideas. Nueva York: Duell, Sloane and Pearce.
León, J.L. (1989). Persuasión de masas. Bilbao: Deusto.
Lippmann, W. (1922). Public Opinion. New York: Macmillan.
Lofland, J. y Lofland, L.H. (1984). Analyzing social settings. Belmont, Wodsworth: Publishing Company.
López de Zuazo, A. (1985). Diccionario del Periodismo. Algar. Madrid: Pirámide.
Martin CH. R. y Oshagan, H. (1997). Disciplining the workforce: The news media frame a General Motors plant closing. Communication Research, 24(6), 669-697.
Martin, H. (1936). Nationalism and children's literature. Library quarterly, 6, 405-418.
Martínez Arias, R. (1995). Psicometría: Teoría de los tests psicológicos y educativos. Madrid: Síntesis.
Matthews, B. C. (1910). A study of a New York daily. Independent 68. 82-86.
Mc Quail, D. (1975). Communication. Longman, Londres.
Mc Quail, D. (1984). Mass communication theory: an introduction. Thousand Oaks, CA, Sage.
McDiarmin, J. (1937). Presidential inaugural addresses: a study in verbal symbols. Public Opinion Quarterly, 1. 79-82.
Monzón Arribas, C. (1990). La opinión pública. Teorías, concepto y métodos. Madrid, Ed. Tecnos, S.A.
Mühr, T. (1991) ATLAS/ti: A prototype for the support of text interpretation. Qualitative Sociology, 14, 349-371.
Noelle-Neumann, E. (1973). Return to the Concep of Powerful Mass Media. Studies of Broadcasting, 4.
Pool, I. De Sola (1959). Trends in Content Analysis. Urbana: University of Illinois Press.
Potter, W. J., Warren, R., Vaughan, M., Howley, K., Land, A. y Hagemeyer, J. (1997). Antisocial acts in reality programming on television. Journal of Broadcasting and Electronic Media, 41(1), 69-89.
Pratkanis, A. y Aronson, E. (1994). La era de la propaganda. Barcelona: Paidós.
QSR (1994). Qualitative Data Analysis for Research Profesionals. Victoria: Autor
Reardon, K. K. (1991). La persuasión en la comunicación. Barcelona: Paidós.
Richards , L. y Richards, T. (1991). The Transformation of Qualitative Methods: Computational Paradigms and Research Processes. EnFielding, N. y Lee, R. Using Computers in Qualitative Research, (38-53).
Richards , T.J. y Richards, L. (1994). Using Computers in Qualitative Research. En N. K. Denzin, E. y Lincoln, Y. S., Hadbook of Qualitative Research. (:445-462). Londres: SAGE Publications.
Roberts, J. V. y Grossman, M. G. (1990). Crime prevention and public opinion. Canadian Journal of Criminology, 32 (1), 75-90.
Rodrigo Alsina, M. (1989). La construcción de la noticia. Barcelona. Paidós.
Rodríguez Gómez, G;, Gil Flores, J;, García Jiménez, E. y Etxeberría Murgiondo, J. (1995). Análisis de datos cualitativos asistido por ordenador: Aquad y Nudist. Barcelona: PPU.
Sebeok, T. A. y Zeps, V. J. (1958). An analysis of structured content with application of electronic computer research in psycholinguistics. Languaje and Speech, 1, 181-193.
Seidel, J. V., Kjoselyh, R. y Seymour, E. (1988). The Ethnograph: AUser's Guide. Amherst, MA: Qualis Research Associates.
Shannon, C., Weaver, W. (1949). The Mathematical theory of Communication. University of Illinois Press, Urbana.
Shaw, E. (1979). Agenda-setting and Mass Communication theory. International Journal for Mass Communication Studies, XXV (2).
Shelly, A. Y Sibert, G. (1985). The QUALOG user´s manual. Syracuse, NY: Syracuse University, School of Computer and Information Science.
Simpson, G. E. (1934). The Negro in the Philadelphia press. Ph. D. dissertation, University of Pennsylvania.
Smith, E. R. y Mackie, D. M. (1990). Psicología social. Madrid: Panamericana.
Speed, G. J. (1893). Do newspapers now give the news?. Forum, 15, 705-711.
Street, A. T. (1909). The truth about newspapers. Tribune (Julio 25) Chicago
Taylor, S.J. y Bogdan, R. (1986). Introducción a los métodos cualitativos en investigación. Buenos Aires: Paidós.
Tenney, A. A. (1912). The scientific analysis of the press. Independent, 73, 895-898.
Tesch, R. (1991). Qualitative Research: Analysis Types and Sofware Tools. Bristol: The Falmer Press.
Tójar , J.C. (1993). Concordancia en los registros de observación. Barcelona: PPU.
Tójar , J.C. y Serrano, J. (1996). Análisis secuencial de datos observacionales en investigación educativa (Y II): Perspectiva multivariante con modelos log-lineales y logit. Revista de Investigación Educativa, 14, (1) 97-114.
Tuchman, G. (1978). La producción de la noticia. Barcelona. Gustavo Gili
Upton, G. (1978). The analysis of cross-tabulated data. New York: John Willey.
Van Dijk, T. (1990). La noticia como discurso Comprensión, estructura y producción de la información. Barcelona: Paidós Ibérica, S.A.
Walworth, A. (1938). Social Histories at war: A study of the Treatement of Our Wars in the SecondarySchool History Books Former Enemies. Cambridge, MA: Harvard University Press.
White, P. W. (1924). Quarter century survey of press content shows demand for facts. Editor and Publisher, 57, mayo 31.
White, R. K. (1947). Black Boy, a value analysis. Journal of Abnormal and Social Psychology, 42, 440-461.
Wilcox, D. F. (1990). The American newspaper: a study in social psychology. Annals of American Academy of Political and Social Science, 16, 56-92.
Wolf, M. (1991). La Investigación en la comunicación de masas. Crítica y perspectivas. Barcelona: Paidós.
Woodward, J. L. (1934). Quantitative newspaper analysis and technique of opinion research. Social Forces, 12, 526-537.
Wright, C. R. (1960). Functional Analysis and Mass Communication. Public Opinion Quarterly, 24.
Ysewijn, P. (1996). Generalizability Study. Versión 2.0.E.
| Inicio |
| |
|
|---|---|
|
revista
digital · Año 9 · N° 63 | Buenos Aires, Agosto 2003 |
|