
|
|
|---|---|
|
¿Qué es la informática aplicada a las ciencias del deporte?
|
|
|
http://www.efdeportes.com/ Revista Digital - Buenos Aires - Año 6 - N° 33 - Marzo de 2001 | |
2 / 8
Análogamente, un sistema experto posee un motor de inferencia que es el que se encarga de implementar las funciones de razonamiento.
En esta analogía el proceso realizado por el motor de inferencia imita ciertos aspectos del pensamiento, mientras que el conocimiento es almacenado en ultima instancia en la base de conocimientos. En cierta manera la diferencia entre el motor de inferencia y la base de conocimiento en un sistema experto es la misma que la distinción entre los métodos de razonamiento de propósito general y el conocimiento específico a cada dominio que se ha construído en el campo de la inteligencia artificial. El conocimiento general sobre la manera de resolver los problemas se refleja en la manera de operar del motor de inferencia. De esta manera un motor de inferencia puede ser usado para razonar sobre distintas bases de conocimiento, siempre que el conocimiento esté codificado según las mismas reglas.
Además de estos dos elementos, el entorno de un sistema experto incluye varias herramientas para asistir a las personas que construyen o utilizan el sistema experto. A la hora de construir, el desarrollador utiliza herramientas para adquirir, codificar y limpiar el conocimiento con el que se alimenta a la base de conocimientos. Una vez que el sistema experto ha sido desarrollado los usuarios se valen de una serie de herramientas e interfaces para interactuar, consultar y actualizar el sistema experto. En muchas ocasiones los sistemas expertos pueden ser integrados en entornos de tiempo real, grandes bases de datos o ser parte de aplicaciones más grandes.
El interfaz de usuario de un sistema experto permite que los usuarios pregunten al sistema, le proporcionen información, reciban consejo, etc. Dentro de las limitaciones de los computadores, este interfaz busca en alguna manera suministrar el mismo conjunto de facilidades de comunicación que un experto humano. Del mismo modo que un experto humano explica sus decisiones y recomendaciones, los sistemas expertos también necesitan justificar y explicar sus acciones. La parte de un sistema experto que genera estas justificaciones se denomina herramienta de explicación. Esta herramienta no sólo satisface la necesidad social de reasegurar la confianza del usuario final en el sistema, sino que también, desde el punto de vista técnico, le sirve al desarrollador para realizar un seguimiento del sistema experto y conocer la validez del conocimiento introducido en la base del conocimiento.
2.3.2. Algoritmos Genéticos
¿Qué son los algoritmos genéticos?
Los algoritmos genéticos (GAs) fueron inventados para imitar algunos procesos observados en los mecanismos de evolución natural. Mucha gente, incluidos biólogos, se sorprenden del hecho de que la vida y su complejidad podrían haber evolucionado en un periodo de tiempo relativamente corto según los registros fósiles. La idea de los GAs es utilizar los principios del concepto de evolución para resolver problemas de optimización. El padre de los GAs es John Holland que los inventó al principio de los 70.
Los GAs son algoritmos adaptativos de búsqueda heurística basados en los principios evolutivos. Como tales representan un aprovechamiento inteligente de las búsquedas aleatorias usadas para resolver problemas de optimización. Aunque tienen un componente aleatorio, los GAs no tienen un comportamiento aleatorio, sino que explotan la información histórica (evolutiva) para dirigir un proceso de búsqueda hacia regiones del espacio de búsqueda con más posibilidades de optimizar un problema. Los principios básicos de funcionamiento de los GAs se basan en la creación de una población de individuos (soluciones a un problema), selección de los más adaptados (soluciones más cercanas al óptimo) y recombinación de los individuos más adaptados para crear una nueva población (integración de soluciones).
En muchos casos, los algoritmos genéticos ofrecen resultados más satisfactorios que otras técnicas usadas en Inteligencia Artificial. Esto es debido a que son mucho más robustos (mayor tolerancia en los datos de entrada o ruido), y ofrecen un método generalmente eficaz en la exploración de espacios de búsqueda complejos (alta dimensionalidad).
¿Cómo funcionan?
Los GAs simulan el proceso de supervivencia de los individuos mejor adaptados en generaciones consecutivas para resolver un problema. Cada generación consiste en una población de cadenas de caracteres o de bits que representan una solución (numérica o codificada) a un problema dado y que evocan a las cadenas de DNA que observamos en los cromosomas. Cada individuo (cadena de bits) representa un punto en un espacio de búsqueda y por tanto una posible solución. Cada población es sometida al proceso de evolución. Los principios evolutivos que se pretenden simular son los siguientes:
Los individuos en una población compiten por los recursos disponibles y se reproducen.
Los individuos más adaptados en cada competición producen más descendientes que los individuos menos adaptados.
La información genética de los individuos mejor adaptados se propaga en generaciones sucesivas de forma que dos padres "buenos" producirán en algunas casos descendientes que son mejor adaptados que ellos mismos.
De esta manera cada generación sucesiva estará mejor adaptada a su entorno.
En términos generales, el espacio de búsqueda de un problema consiste en el conjunto de todas las posibles soluciones al problema. De todas esas posibles soluciones solo una, o unas pocas son las que optimizan el problema según algún criterio dado. En GAs se empieza por tanto por obtener un método de codificación de las posibles soluciones en cadenas de caracteres sobre un determinado alfabeto (suele ser el alfabeto binario). Luego se define una función de evaluación que a cada individuo (posible solución) asigna un valor de eficacia o adaptación, de forma que se pueden comparar distintos individuos para saber cual esta mejor adaptado. Esta función, representa el entorno en al cual los individuos han de adaptarse. Una vez definido esto, se comienza por una población de posibles soluciones (normalmente generada de manera aleatoria) y se repite el siguiente proceso:
Se le aplica la función de evaluación a cada individuo, de manera que se obtiene una medida objetiva de la capacidad de adaptación de cada individuo a esa función.
Se selecciona una porción de la población basada en la medida anterior. Por ejemplo, a cada individuo se le asigna una probabilidad proporcional a su medida de adaptación y se seleccionan individuos según esa probabilidad. De esta manera se seleccionarán los individuos que estén mejor adaptados y ocasionalmente también se seleccionará algún individuo con una adaptación menor. Esto se suele hacer para no perder la opción de evitar máximos locales en la función de evaluación.
Los individuos seleccionados se reproducen entre ellos para generar una nueva población. Hay muchos tipos de operadores para realizar este paso. Entre ellos los más comunes son: el cruce, en el que las cadenas de bits se intercambian porciones y la mutación, en el que de forma aleatoria se cambian de valor algunos bits de algunos individuos. Como se puede observar, el cruce corresponde a la recombinación de información de las posibles soluciones, y la mutación corresponde a la introducción de nueva información en la población.
De esta manera se producen nuevas generaciones de soluciones que contienen, por lo general, más genes buenos que una solución típica de la generación anterior. Cada generación contendrá más y mejores soluciones parciales que las generaciones previas. En algún momento el proceso alcanza el máximo deseado o algún valor que hace que las sucesivas generaciones no mejoren las anteriores.
Como se puede observar, los GAs son un buen método para buscar las soluciones a un problema cuando no se tiene mucha información acerca del dominio o cuando no se conoce un método eficaz de exploración del espacio de soluciones. Por supuesto los GAs no son métodos infalibles para la resolución de problemas, ni los más eficaces en muchos casos, pero son muy válidos en entornos en los que los espacios de búsquedas son complejos. También, es importante observar que no existe ningún teorema de convergencia de los GAs y por tanto no es posible saber a priori si encontrarán una solución en un caso específico. Ni siquiera, es posible asegurar en muchos casos si la solución que proporcionan son máximos globales o simplemente máximos locales.
2.3.3. Análisis y clasificación automática de datos
¿Qué es el aprendizaje automático y la minería de datos?
En las últimas décadas investigadores provenientes de distintas disciplinas, desde la Psicología hasta la inteligencia artificial, han intentado desarrollar modelos generales de muchos de los procesos cognitivos que realizan los humanos, especialmente el aprendizaje. Muchos de estos esfuerzos generaron ideas y aplicaciones interesantes no sólo desde el punto de vista teórico sino también desde las perspectivas tecnológicas y prácticas. En particular, los avances en la representación del conocimiento y las nociones y técnicas de aprendizaje automático abren muchas posibilidades en el campo de la representación y análisis de datos. Basados en estos conceptos y sin olvidar los métodos estadísticos tradicionales de análisis de datos, en la última década han surgido nuevos métodos alternativos aplicables en estos campos.
Muchos de estos métodos comparten un uso intensivo de los recursos computacionales disponibles hoy en día. Evidentemente, esto no era posible hace algunas décadas. El planteamiento general del problema que se aborda en esta sección es el siguiente: partiendo de un conjunto (amplio) de datos, las metodologías automáticas permiten desarrollar representaciones convenientes de las estructuras de los datos. El conocimiento adquirido puede ser entonces aplicado en otros conjuntos de datos bajo la hipótesis que comparten características (por ejemplo, el origen) similares. En muchas ocasiones (y más aún con la ayuda de las computadoras) las metodologías de adquisición de datos proporcionan grandes cantidades de datos (que no información) generadas por muchas clases de eventos que se monitorizan. Desde el punto de vista del investigador esos datos son imprescindibles porque son el origen último de su tarea, pero en sí son inútiles si no es posible extraer informaciones de ellos (tales como correlaciones escondidas, particiones, determinación de variables significativas, etc.). De esta forma el investigador ha de tener los medios para transformar los datos brutos en conocimiento. La siguiente figura representa este proceso automático:

Con los medios actuales, la cantidad de datos abruman en muchas ocasiones al investigador e inutilizan los métodos manuales tradicionales de extracción de información. Ejemplo de esto lo dan la física de partículas (experimentos que general mas de 1 Megabyte de información por segundo), el análisis de mercados comerciales (cantidad de empresas, valores y sectores comerciales), etc.
Dentro de las técnicas de aprendizaje automático, se denomina minería de datos a las técnicas que permiten obtener las mejores representaciones de los datos, dados unos criterios específicos. En cierta parte, la idea es similar a los procesos de descubrimiento que se realizan en el ámbito del método científico. Por eso, estas técnicas reciben a veces el nombre de descubrimiento automático.
¿Cómo funciona?
En sí la minería de datos no es más que una metodología de resolución de problemas que trata de encontrar descripciones matemáticas o lógicas de patrones y regularidades de una cierta complejidad en conjuntos de datos. Hay dos maneras principales de realizar este proceso.
Por un lado el aprendizaje supervisado, las regularidades en los datos se encuentran explorando casos conocidos que se presume que contienen o implican los patrones bien definidos. Una vez se realiza esta exploración inicial y se establecen los patrones relevantes, se realiza un proceso de generalización para su aplicabilidad con cualquier conjunto de datos. Por otro lado, el aprendizaje no supervisado encuentra regularidades en los datos en base a algunos caracterizaciones lógicas de carácter general. Podemos, por tanto, representar la minería de datos como un proceso que puede ser bien sintético (generalizando a partir de algunos casos conocidos) o analítico (generando descripciones de alto nivel).
La minería de datos permite producir conocimiento científico en áreas que aún no son propicias para las aproximaciones tradicionales. De esta forma los algoritmos de optimización y aprendizaje se pueden usar para producir modelos de datos experimentales en áreas en las que no existen explicaciones ni modelos teóricos previos.
La noción básica del aprendizaje supervisado es la de un clasificador, que es un algoritmo o sistema capaz de discriminar datos entre un conjunto de posibles categorías. Los clasificadores se entrenan y se prueba con un conjunto de casos conocidos y crean sus propias estructuras y reglas internas a medida que se les presentan los casos conocidos. De esta manera, y con un número suficiente de casos conocidos, el clasificador se convierte en un generalizador y es capaz de clasificar correctamente datos provenientes de casos desconocidos. Por tanto la utilización del aprendizaje supervisado se basa en dos pasos:
La creación de un conjunto determinado de categorías en las cuales clasificar los datos
La presentación de pares [dato, clasificación] que corresponden a los casos conocidos. Durante este proceso el clasificador va formándose sus criterios internos de clasificación.
Esto es el entrenamiento.La presentación de datos ya generalizados proporciona la clasificación automática en base a los criterios internos adquiridos en la fase anterior.
Esto es la operación.
Por el contrario, el aprendizaje no supervisado no parte de criterios específicos preestablecidos (como lo son el conjunto de categorías en las que se dividen los casos conocidos), sino que parte de descripciones generales del tipo de patrones que reconocer en los datos. Por ejemplo, mientras que en el aprendizaje supervisado lo que el investigador determina a priori es: existen las categorías A, B y C, con este significado; en el aprendizaje no supervisado el investigador únicamente dice: existirán entre 4 y 6 categorías y el clasificador se encarga de agrupar los datos.
La implementación final de los clasificadores se basa en muchas ocasiones en redes de neuronas artificiales. Las redes de neuronas artificiales están compuestas por elementos que siguen los principios de funcionamiento de las neuronas naturales: reciben varios valores de entrada y en base a esos valores ofrecen un único valor de salida (encendido o apagado). De esta forma se construyen redes de neuronas conectando la salida de unas neuronas a las entradas de otras. La redes pueden adquirir diversas configuraciones, pero generalmente un conjunto de neuronas de la forma siguiente:
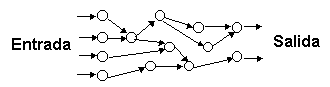
En donde hay una serie de neuronas que reciben los datos de entrada y otras neuronas cuyo estado de activación conforma el dato de salida. En algunas configuraciones existen capas organizadas de neuronas (aparte de la capa de entrada y de salida), en otras existen ciclos, etc. Cada conexión entre dos neuronas tiene unas características específicas que determinan la influencia en la neurona a la que llega la conexión. Un aprendizaje supervisado proporciona valores de entrada, calcula el error en la salida y mediante un algoritmo corrector cambia las características de las conexiones con cada par [dato, clasificación] que se le presenta. Un aprendizaje no supervisado cambia las características de las conexiones según se va usando la red, por ejemplo, reforzando las conexiones mas usadas.
Es importante observar que el origen de las redes neuronales es imitar el funcionamiento básico de las neuronas naturales, y se desconoce bastante el porqué fundamental del comportamiento de las mismas. Experimentando con ellas se ha descubierto que funcionan muy bien como discriminadoras de información, pero sin saber exactamente cómo deducir ese comportamiento global del funcionamiento particular de cada neurona del conjunto.
Desde el punto de vista práctico y dependiendo de la envergadura de cada problema, con unos pocos conocimientos de programación es posible construir redes neuronales relativamente sencillas y probar su funcionamiento directamente. También existen herramientas con diversos grados de sofisticación para diseñar, entrenar y explotar redes neuronales. También existen herramientas sofisticadas que implementan un contexto entero de aprendizaje automático, con los conceptos de clasificadores y generalizadores, y en los que las redes neuronales no son más que una parte específica de su diseño. En cualquier caso, es importante saber ser consciente de la base de estas ideas, para poder adquirir criterios válidos en cuanto a sus limitaciones y posibilidades.
2.3.4. Simulaciones y Realidad Virtual
¿Qué es la realidad virtual?
El término Realidad Virtual es usado por mucha gente con distintos significados. Para algunos no es más que un casco con una pantalla, un guante sensible y sonido estéreo y para algunos otros son los efectos especiales que se ven en una película. Una definición más objetiva sin embargo, es la que se ofrece en [5] y es la siguiente:
La Realidad Virtual es un modo para que los humanos podamos ver, manipular e interactuar con datos extremadamente complejos y con los ordenadores.
En seguida vemos la conexión con el resto de los conceptos que hemos estado tratando en este capítulo. La parte de la definición que habla de la visualización se refiere al ordenador que genera información visual, auditiva o en algunos otros sentidos sobre un mundo dentro del ordenador. Este mundo puede ser un modelo arquitectónico, una simulación científica, una vista en una base de datos, etc. El usuario puede interactuar con el mundo y manipular los objetos de los que está compuesto ese mundo. Estos objetos pueden ser representaciones de entidades físicas (por ejemplo, un corredor en acción o una simulación de vuelo) o entidades abstractas (conceptos y relaciones científicas, tendencias de mercados, etc.) Lo importante es que conforma un medio por el cual se facilita la interacción con conjuntos de datos cuyas relaciones son complejas y no del todo entendibles de manera inmediata
Componentes de un sistema de realidad virtual
Según los requerimientos y el entorno en el que funciona un sistema de realidad virtual cambian las exigencias de eficacia de cada una de las partes que a continuación describimos. Por ejemplo, si creamos una simulación para estudiar la aerodinámica de una posición determinada de un ciclista lo importante es la exactitud del modelo y la adaptación de la simulación a las variables que tomamos como criterios. La velocidad de la simulación, aunque muy conveniente, no es una característica fundamental del estudio. Pero si por ejemplo, creamos una simulación para entrenar a un corredor a adquirir un cierto reflejo, lo importante es que la simulación sea en tiempo real. Con esto en mente, las principales partes de un sistema de realidad virtual son:
| Lecturas: Educación Física y Deportes · http://www.efdeportes.com · Año 6 · Nº 33 | sigue Ü |